导语:
在C/C++中,开发者需要手动地管理在堆中分配的内存,但是这往往导致很多问题。
1、 内存分配之后忘记释放,造成内存泄漏。
2、 非法访问那些已经释放了的内存,引发程序崩溃。
没有一个好的C/C++应用程序开发框架,一般的开发者根本无法驾驭内存问题,因为程序大了之后,很容易造成失控。最要命的是,内存被破坏的时候,并不一定就是程序崩溃的时候,它就是一颗不定时炸弹,说不准什么时候会被引爆,查找原因也是非常困难的。Java 语言运行在虚拟机上,虚拟机可以自动回收那些不再使用了的Java Object,也就是那些不再被引用了的Java Object。 这就是Java语言的一种重要特性--垃圾自动收集机制。 垃圾回收机制将开发者从内存问题中解放出来,极大地提高了开发效率,以及提高了程序的可维护性。这也是Android为什么会选择Java而不是C/C++来作为主要应用程序开发语言的原因之一。就是为了能够让开发远离内存问题,而将精力集中在业务上,开发出更多更好的APP来,从而迎头赶超。Android系统内存也存在大量的C/C++代码,这只要考虑性能问题, 不过,为了避免出现内存问题,在Android系统内部的C++代码,大量地使用了来自动管理对象的生命周期。选择Java来作为Android应用程序的开发语言,可以说是技术与商业之间一个折衷,事实证明,这种折衷是成功的。
在GingerBread(android2.3)之前,Dalvik虚拟使用的垃圾收集机制有以下特点:
1. Stop-the-world,也就是垃圾收集线程在执行的时候,其它的线程都停止;
2. Full heap collection,也就是一次收集完全部的垃圾;
3. 一次垃圾收集造成的程序中止时间通常都大于100ms。
GingerBread(android2.3)---Kit Kat(4.4),Dalvik虚拟使用的垃圾收集机制得到了改进
1. Cocurrent GC : 也就是大多数情况下,垃圾收集线程与其它线程是并发执行的
2. Partial collection,也就是一次可能只收集一部分垃圾;
3. 一次垃圾收集造成的程序中止时间通常都小于5ms。
Kit Kat(4.4以上版本),Android开始使用ART替代Dalivk虚拟机, ART的垃圾回收机制有一次做了优化
特点和Dalivik基本一致,效率上比Dalivik更优!!!
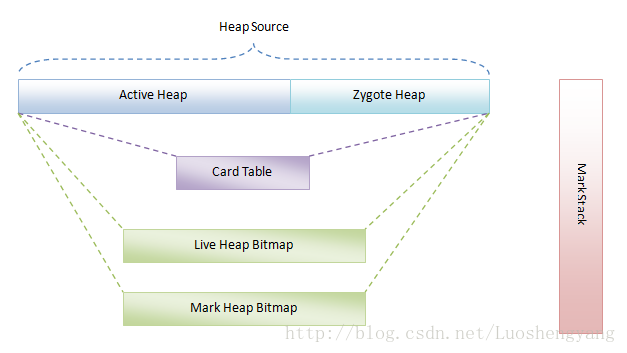 图1 Dalvik虚拟机垃圾收集机制的基本概念
图1 Dalvik虚拟机垃圾收集机制的基本概念 所有的java对象都是在Dalivik堆上面申请的, Dalivik堆分为两部分。 Active Heap 和 Zygote Heap。 事实上,Dalvik虚拟机的堆最初是只有一个的,也就是Zygote进程在启动过程中创建Dalvik虚拟机的时候,只有一个堆。 但是当Zygote进程在fork第一个应用程序进程之前,会将已经使用了的那部分堆内存划分为一部分,还没有使用的堆内存划分为另外一部分。前者就称为Zygote堆,后者就称为Active堆 堆位图,用于记录android中所有应用程序的Java 对象的引用情况。 两个Bitmap来描述堆的对象的状态。 一个称为Live Bitmap,另一个称为Mark Bitmap。 Heap Bitmap使用位图来标记对象是否被使用。如果一个对象被引用,那么在Bitmap中与它对应的那一位就会被设置为1。否则的话,就设置为0。 Live Bitmap用来标记上一次GC时被引用的对象,也就是没有被回收的对象,而Mark Bitmap用来标记当前GC有被引用的对象。 有了这两个信息之后,我们就可以很容易地知道哪些对象是需要被回收的,即在Live Bitmap在标记为1,但是在Mark Bitmap中标记为0的对象。 在垃圾收集的Mark阶段,要求除了垃圾收集线程之外,其它的线程都停止,否则的话,就会可能导致不能正确地标记每一个对象。这种现象在垃圾收集算法中称为Stop The World,会导致程序中止执行,造成停顿的现象。为了尽可能地减少停顿,我们必须要允许在Mark阶段有条件地允许程序的其它线程执行。这种垃圾收集算法称为并行垃圾收集算法Concurrent GC。为了实现Concurrent GC,Mark阶段又划分两个子阶段。 在Mark阶段,Dalvik虚拟机能过递归方式来标记对象。但是,这不是通过函数的递归调用来实现的,而是借助一个称为Mark Stack的栈来实现的。 1. 为什么要把用来分配对象的堆划分为Active堆和Zygote堆 ? Android系统的第一个Dalvik虚拟机是由Zygote进程创建的。 应用程序进程是由Zygote进程fork出来的。也就是说,应用程序进程使用了一种写时拷贝技术(COW)来复制了Zygote进程的地址空间。这意味着一开始的时候,应用程序进程和Zygote进程共享了同一个用来分配对象的堆。 然而,当Zygote进程或者应用程序进程对该堆进行写操作时,内核就会执行真正的拷贝操作,使得Zygote进程和应用程序进程分别拥有自己的一份拷贝。拷贝是一件费时费力的事情。 因此,为了尽量地避免拷贝,Dalvik虚拟机将自己的堆划分为两部分。事实上,Dalvik虚拟机的堆最初是只有一个的。也就是Zygote进程在启动过程中创建Dalvik虚拟机的时候,只有一个堆。 但是当Zygote进程在fork第一个应用程序进程之前,会将已经使用了的那部分堆内存划分为一部分,还没有使用的堆内存划分为另外一部分。前者就称为Zygote堆,后者就称为Active堆。 以后无论是Zygote进程,还是应用程序进程,当它们需要分配对象的时候,都在Active堆上进行。这样就可以使得Zygote堆尽可能少地被执行写操作,因而就可以减少执行写时拷贝的操作。 在Zygote堆里面分配的对象其实主要就是Zygote进程在启动过程中预加载的类、资源和对象了。这意味着这些预加载的类、资源和对象可以在Zygote进程和应用程序进程中做到长期共享。这样既能减少拷贝操作,还能减少对内存的需求。 图2 Dalvik虚拟机的堆
在Dalvik虚拟机中,堆实际上就是一块匿名共享内存。Dalvik虚拟机并不是直接管理这块匿名共享内存,而是将它封装成一个mspace,交给C库来管理。 mspace 是libc中的概念,我们可以通过libc提供的函数create_mspace_with_base创建一个mspace,然后再通过mspace_开头的函数管理该mspace。 例如,我们可以通过mspace_malloc和mspace_bulk_free来在指定的mspace中分配和释放内存。 实际上,我们在使用libc提供的函数malloc和free分配和释放内存时,也是在一个mspace进行的,只不过这个mspace是由libc默认创建的。 Dalvik虚拟机除了要给应用层分配对象之外,最重要的还是要对这些已经分配出去的对象进行管理,也就是要在对象不再被使用的时候,对其进行自动回收。 Dalvik虚拟机执行完成一次垃圾收集之后,我们通常可以看到类似以下的日志输出:
D/dalvikvm(9050): GC_CONCURRENT freed 2049K, 65% free 3571K/9991K, external 4703K/5261K, paused 2ms+2ms
3、 3571K/9991K表示Java Object Heap统计,即在9991K的Java Object Heap中,有3571K是正在使用的 4、 4703K/5261K表示External Memory统计,即在5261K的External Memory中,有4703K是正在使用的
5、 2ms+2ms表示垃圾收集造成的程序中止时间。 Dalivk垃圾收集的使用的 耳熟能详,大名鼎鼎的的Mark-Sweep算法。 Mark-Sweep垃圾收集算法主要分为两个阶段:Mark和Sweep。 1.Mark阶段从对象的根集开始标记 被引用的对象 。标记完成后,就进入到Sweep阶段 2.Sweep阶段所做的事情就是回收没有被标记的对象占用的内存。 下面我们来介绍一下在
Mark和Sweep 过程中 堆管理的结构体的作用 这里涉及到的一个核心概念就是我们怎么标记对象有没有被引用的,换句说就是通过什么 来描述对象有没有被引用。是的,就是图1中的Heap Bitmap了。Heap Bitmap的结构如图3所示: 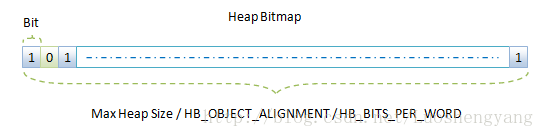 图3 Heap Bitmap
图3 Heap Bitmap 1、在Dalvik虚拟机中, 使用一个unsigned long数组 来描述一个Heap Bitmap。 2、我们使用libc提供的函数mspace_malloc来从堆里面分配内存时,得到的内存的地址总是对齐到HB_OBJECT_ALIGNMENT(8)的 ,也就是说,我们分配的对象的地址的最低三位总是0。 为了减少 Bitmap的大小。 Bitmap中的位与对象的对应关系时,忽略最低三位。 在垃圾收集的Mark阶段,要求除了垃圾收集线程之外,其它的线程都停止,否则的话,就会可能导致不能正确地标记每一个对象。这种现象在垃圾收集算法中称为Stop The World,会导致程序中止执行,造成停顿的现象。 为了尽可能地减少停顿,我们必须要允许在Mark阶段有条件地允许程序的其它线程执行。这种垃圾收集算法称为并行垃圾收集算法Concurrent GC。 为了实现Concurrent GC,Mark阶段又划分两个子阶段。 1、第一阶段:只负责标记根集对象。所谓的根集对象,就是指在GC开始的瞬间,被全局变量、栈变量和寄存器等引用的对象。 2、 第二阶段:负责 标记被根集对象引用的对象的过程就是。 有了这些根集变量之后,我们就可以顺着它们找到其余的被引用变量。例如,一个栈变量引了一个对象,而这个对象又通过成员变量引用了另外一个对象,那该被引用的对象也会同时标记为正在使用。 在Concurrent GC,第一个子阶段是不允许垃圾收集线程之外的线程运行的,但是第二个子阶段是允许的。 不过,在第二个子阶段执行的过程中,如果一个线程修改了一个对象,那么该对象必须要记录起来,因为它很有可能引用了新的对象,或者引用了之前未引用过的对象。如果不这样做的话,那么就会导致被引用对象还在使用然而却被回收。 这种情况出现在只进行部分垃圾收集的情况,这时候Card Table的作用就是用来记录非垃圾收集堆对象对垃圾收集堆对象的引用。 Dalvik虚拟机进行部分垃圾收集时,实际上就是只收集在Active堆上分配的对象。 因此对Dalvik虚拟机来说,Card Table就是用来记录在Zygote堆上分配的对象在部收垃圾收集执行过程中对在Active堆上分配的对象的引用。 我们是不是想到再用一个Bitmap在描述上述第二个子阶段被修改的对象呢?虽然我们尽大努力减少了用来标记对象的Bitmap的大小,不过还是比较可观的。 因此,为了减少内存的消耗,我们使用另外一种技术来标记Mark第二子阶段被修改的对象。 这种技术使用到了一种称为Card Table的数据结构,如图4所示: 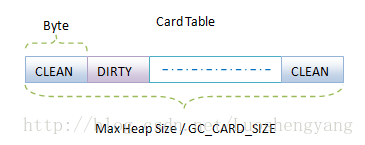 图4 Card Table
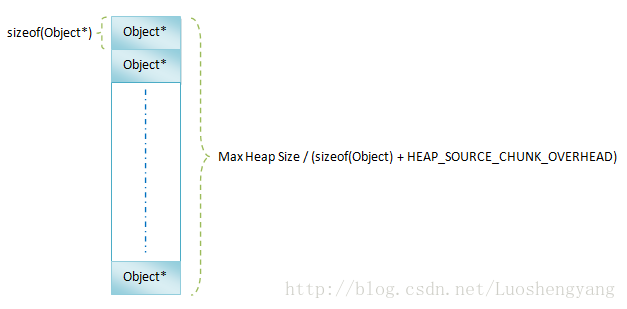
图4 Card Table 从名字可以看出,Card Table由Card组成,一个Card实际上就是一个字节,它的值要么是CLEAN,要么是DIRTY。 如果一个Card的值是CLEAN,就表示与它对应的对象在Mark第二子阶段没有被程序修改过。否则的话,就意味着被程序修改过,对于这些被修改过的对象。需要在Mark第二子阶段结束之后,再次禁止垃圾收集线程之外的其它线程执行,以便垃圾收集线程再次根据Card Table记录的信息对被修改过的对象引用的其它对象进行重新标记。 由于Mark第二子阶段执行的时间不会太长,因此在该阶段被修改的对象不会很多,这样就可以保证第二次子阶段结束后,再次执行标记对象的过程是很快的,因而此时对程序造成的停顿非常小。 在Card Table中,在连续GC_CARD_SIZE地址中的对象共用一个Card。Dalvik虚拟机将GC_CARD_SIZE的值设置为128。因此,假设堆的大小为Max Heap Size,那么我们只需要一块字节数为(Max Heap Size / 128)的Card Table。相比大小为(Max Heap Size / 8 / 32)× 4的Bitmap,减少了一半的内存需求。 在Mark阶段,Dalvik虚拟机能过递归方式来标记对象。但是,这不是通过函数的递归调用来实现的,而是借助一个称为Mark Stack的栈来实现的。 具体来说,当我们标记完成根集对象之后,就按照它们的地址从小到大的顺序标记它们所引用的其它对象。 假设有A、B、C和D四个对象,它的地址大小关系为A < B < C < D,其中,B和D是根集对象,A被D引用,C没有被B和D引用。那么我们将依次遍历B和D。当遍历到B的时候,没有发现它引用其它对象,然后就继续向前遍历D对象。发现它引用了A对象。按照递归的算法,这时候除了标记A对象是正在使用之外,还应该去检查A对象有没有引用其它对象,然后又再检查它引用的对象有没有又引用其它的对象,一直这样遍历下去。这样就跟函数递归一样。 更好的做法是将对象A记录在一个Mark Stack中,然后继续检查地址值比对象D大的其它对象。对于地址值比对象D大的其它对象,如果它们引用了一个地址值比它们小的其它对象,那么这些其它对象同样要记录在Mark Stack中。等到该轮检查结束之后,再回过头来检查记录在Mark Stack里面的对象。然后又重复上述过程,直到Mark Stack等于空为止。 这就是我们在图1中显示的Mark Stack的作用,它的具体结构如图5所示: 在Dalvik虚拟机中,每一个对象都是从Object类继承下来的,也就是说,每一个对象占用的内存大小都至少等于sizeof(Object)。 此外,我们通过libc提供的函数 mspace_malloc 为对象分配内存时,libc需要额外的内存来记录被分配出去的内存的信息。 例如,需要记录被分配出去的内存的大小。每一块分配出去的内存需要额外的HEAP_SOURCE_CHUNK_OVERHEAD内存来记录上述的管理信息。因此,在Dalvik虚拟机中,每一个对象的大小都至少为sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD。 这就意味着对于一个大小为Max Heap Size的堆来说,最多可以分配Max Heap Size / (sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD)个对象。于是,在最坏情况下,我们就需要一个大小为(Max Heap Size / (sizeof(Object) + HEAP_SOURCE_CHUNK_OVERHEAD))的Object*数组来描述Mark Stack,以便可以实现上述的非递归函数调用的递归标记算法。